
Gastbeitrag – Semantische Erkennung von Zahlungsdaten als Basis für die Automatisierung von Bezahlprozessen
Banken sollen vor allem eines: innovativer sein. Da sind sich alle einig. Eines der wichtigsten Themen stellt in diesem Zusammenhang der Bezahlprozess bzw. der darin enthaltene Überweisungsvorgang dar. Denn das manuelle Eintippen von Daten wie der IBAN ist nicht nur zeitaufwändig, sondern auch lästig. Eine clevere Semantik-Lösung, die alle für eine Überweisung relevanten Daten automatisch extrahiert, kann Abhilfe schaffen. Doch was bedeutet „Semantik“ eigentlich im Rahmen von Bezahlprozessen und welche Herausforderungen müssen gemeistert werden, um alle zahlungsrelevanten Daten zu erkennen? Warum ist es einfacher die IBAN auszulesen, als den Verwendungszweck korrekt zu identifizieren?
Semantik im Rahmen von Bezahlprozessen
Um eine Überweisung auszuführen, sind verschiedene Parameter notwendig, wie z.B. die Bankverbindung des Empfängers und der Verwendungszweck. Von „semantischer Erkennung“ wird im Rahmen von Bezahlprozessen dann gesprochen, wenn diese Parameter auf Basis von Algorithmen und automatischen Verfahren innerhalb von Dokumenten identifiziert und anschließend extrahiert werden, um sie für den eigentlichen Bezahlvorgang nutzen zu können. So kann es sich beim Verwendungszweck z.B. um eine Rechnungs-, Kunden- oder Auftragsnummer handeln. Entsprechend muss das Wissen implementiert sein, welche Art von Information als „Verwendungszweck“ dienen und wie diese Information automatisch aus einem Dokument extrahiert werden kann. Liegt eine Rechnung nur analog vor, muss sie zunächst digitalisiert werden. Dabei ist es wichtig, dass der Scan gut aufbereitet ist und beispielsweise die gedruckten Zeichen klar zu erkennen sind. Dies ist wichtig, um eine bestmögliche Qualität der Texterkennung zu gewährleisten, die als Ausgangsbasis für jede semantische Analyse dient.
Zahlungsrelevante Parameter
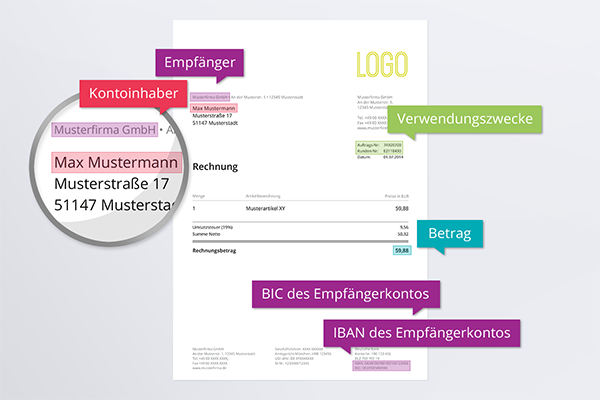
Für einen erfolgreichen Bezahlvorgang sind folgende Parameter notwendig:
• Empfänger der Überweisung
• IBAN des Empfängerkontos
• BIC des Empfängerkontos (optional)
• Betrag
• Verwendungszweck
• Angaben zum Kontoinhaber (optional)
• IBAN des Senders (optional)
Herangehensweisen und Herausforderungen bei der Datenextraktion
Bei der Extraktion von Daten lassen sich verschiedene Herangehensweisen unterscheiden:
- Extraktion von Daten anhand ihrer Position im Dokument
Handelt es sich um einen klassischen Überweisungsträger, weiß man z.B., dass in der ersten Zeile der Empfänger steht, dann die IBAN usw. Dies kann man sich – wie bereits angedeutet – zunutze machen und die Daten entsprechend ihrer Position extrahieren. Dabei muss jedoch auf Details geachtet werden. Ist der Betrag z.B. mit „Sternchen“ umgeben (***** 20,00 *****), dürfen diese Sternchen natürlich nicht mitextrahiert werden. - Extraktion von Daten anhand von Schlüsselwörtern und zugehörigem Wert
Neben der Position im Dokument können Daten auch anhand von Schlüsselwörtern und dem dazugehörigen Wert erkannt und extrahiert werden. Steht auf einem Dokument z.B. „Rechnungsnr: 345628“ weiß man, dass es sich bei der Zeichenkette „345628“ um eine Rechnungsnummer handeln muss, wenn zuvor das Schlüsselwort „Rechnungsnr“ erkannt wurde. Die Herausforderung besteht u.a. darin, zu erkennen, wie weit die Rechnungsnummer reicht, da sie auch Leerzeichen (Rechnungsnr: 2015 06 1278) oder andere Zeichen enthalten kann. Um solche Muster zu erkennen, kann man z.B. entsprechende Grammatiken schreiben und implementieren oder man bedient sich Methoden aus dem Bereich des maschinellen Lernens. - Extraktion von Daten anhand eines festgelegten Formats
Einfacher stellt es sich dar, wenn die zu extrahierenden Daten einem genau festgelegten Format entsprechen und immer gleich aufgebaut sind, wie z.B. die IBAN. In diesem Fall kann ein Suchalgorithmus implementiert werden, der alle Zeichenketten extrahiert, die genau diese Spezifikation aufweisen. Wird auf einem Dokument mehr als eine IBAN erkannt, kann anhand der Prüfziffer validiert werden, welche die richtige ist.. - Extraktion von Daten anhand mehrerer unterschiedlicher Parameter
Deutlich komplexer ist z.B. die Extraktion des Zahlungsempfängers aus einer klassischen Rechnung ohne Überweisungsträger. Dabei gilt es zunächst zu beachten, dass es sich beim Zahlungsempfänger in der Regel um den Absender der Rechnung handelt. Anschließend müssen verschiedene Parameter untersucht werden, die auf den Absender hindeuten können. So kann z.B. als erstes nach einer Adresse gesucht und im zweiten Schritt geprüft werden, ob in der Umgebung dieser Adresse Zeichenketten auftreten, bei denen es sich um den Absender handeln kann. Bei der Suche nach der Adresse kann man u.U. auch auf externe Quellen zurückgreifen, wie z.B. Datenbanken mit Städten und Postleitzahlen oder Firmendaten.Eine besondere Herausforderung kann auch die Erkennung des Gesamtbetrags darstellen. Denn zum einen muss geprüft werden, ob eine Rechnung überhaupt noch bezahlt werden muss. Zum anderen gilt es oft, aus einer Vielzahl an potenziellen Überweisungsbeträgen den richtigen auszuwählen. So können auf einer Rechnung z.B. der Brutto- und Nettobetrag aber auch evtl. Abschlagszahlungen, Beträge für Ratenzahlungen, Rabatte oder Teilbeträge für bestimmte Zeiträume ausgewiesen sein. Wenn es nicht gelingt, den zu überweisenden Betrag eindeutig zu identifizieren, kann man als letzte Option versuchen, durch Berechnungen den richtigen Betrag zu ermitteln.
Mögliche Fehlerquellen bei der Datenextraktion
Natürlich kann es bei der Extraktion von Daten auch zu Problemen kommen. Diese sind meist auf eine fehlerhafte Texterkennung oder eine falsche/fehlende Identifikation von Schlüsselwörtern zurückzuführen.
- Fehler bei der OCR
Ein grundlegendes Problem besteht darin, dass beim OCR-Prozess Fehler auftreten können, wie z.B. dass der Buchstabe „n“ fälschlicherweise als „m“ erkannt wird oder „1“ als „I“. Tritt der Fehler bei einer Zeichenkette auf, bei der aus dem Kontext darauf geschlossen werden kann, wo der Fehler liegt, kann dieser korrigiert werden. Wenn z.B. eine Zeichenkette erkannt wird, die bis auf ein „I“ alle Kriterien einer IBAN erfüllt, kann davon ausgegangen werden, dass es sich bei „I“ um die Zahl „1“ handelt. Diese Korrekturmöglichkeit besteht jedoch meist nicht, wenn es z.B. darum geht, den Empfänger einer Zahlung zu erkennen. Wird beispielsweise im Anschluss an die Texterkennung „Schmidt Im- und Export“ identifiziert, obwohl „Schmitt Im- und Export“ korrekt wäre, hat man keine Chance, dies zu korrigieren. Aus diesem Grund ist es sehr wichtig, dass das Dokument 1. optimal für den OCR-Prozess aufbereitet wird und 2. die Texterkennung als solche eine hohe Qualität aufweist. - Erkennung von Schlüsselwörtern
Im Hinblick auf die Erkennung von Schlüsselwörtern besteht das grundlegende Problem, dass es für Schlüsselwörter oft sehr viele Alternativen gibt. So kann ein Dokument z.B. anstelle von „Rechnungsnr“ auch die Zeichenfolge „RECHNG NR“, nur „Rechnung“ oder im medizinischen Bereich „Liquidation“ enthalten.
Um Fehler zu vermeiden, gilt es entsprechend zwei Punkte zu beachten: Zum einen muss die Möglichkeit bestehen, das Ergebnis der Datenextraktion überprüfen und ggf. manuell korrigieren zu können. Zum anderen sollte eine gute Semantik-Lösung auf so viele Alternativwörter wie möglich trainiert sein.
Über den Autor
Jürgen Oesterle arbeitet als Senior Semantic Analyst bei organize.me, einem FinTech Start-up aus München, das u.a. eine eigene Semantik-Lösung für Business-Kunden, wie z.B. Banken, entwickelt hat. Er verfügt über mehr als 20 Jahre Erfahrung in der Entwicklung von semantischen Lösungen. Vor seinem Start bei organize.me im Jahr 2014 war er als Senior Computational Linguist und Software Developer bei Microsoft tätig.





auch wenn zwischenzeitlich ein großer Fortschritt in div. Bereichen der “technischen Verarbeitung” auszumachen ist, muss man aber festhalten, dass der gleiche Ablauf (Text) im Jahre 2000 hätte verfasst sein können – nur dass es dann halt BLZ und Konto-Nr. gewesen wären, statt SEPA (IBAN/BIC).
aktuell: scan > OCR > Verarbeitung
Restrisiken sind aus o.g. Gründen vorhanden
Da Onlinebanking (-Zugang) jedoch zwischenzeitlich Standard und somit 100% (!) saubere Daten vorhanden sind, stellt sich die Frage: “step-by-step Denke” noch zeitgemäß?
Warum werden diese (Online-) Daten nicht als Basis-Abgleich/-Bestand* verwendet und lediglich eine Plausibilität mit den ermittelten OCR-Daten. Somit hätte scan-Qualität und OCR-Fehlerkennung plötzlich eine untergeordnete Bedeutung.
*regelmäßige Analyse der Konten – Kumulierung der individuellen Daten
Ein Abgleich mit vorhandenen Daten ist sicherlich sinnvoll, kann aber nur dann durchgeführt werden, wenn die Daten vergleichbar sind. Wenn es sich um eine Überweisung an einen Empfänger handelt, an den noch nie etwas von dem Kontoinhaber überwiesen wurde, kann man nichts abgleichen. Selbst wenn es schon Überweisungen gibt, so ist der Verwendungszweck und der Betrag jedes Mal neu; die Kontodaten sind in diesem Fall abgleichbar und theoretisch könnte man auch Teile des Verwendungszweckes automatisch lernen, da dieser vermutlich immer dem gleichen Muster folgt, doch ist dies nur möglich, wenn es genügend Daten gibt.
Für regelmäßige Überweisungen an den gleichen Empfänger wird man dieses Verfahren meist sowieso nicht einsetzen, sondern den Weg z.B. über eine Lastschrift oder einen Dauerauftrag gehen. Falls dies nicht gemacht wird, ist natürlich ein Abgleich sinnvoll, doch tritt dieser Fall vermutlich nur selten ein.
Herr Oesterle, Ihre Punkte sind zweifellos korrekt, ebenso wie Ihr og. Bericht.
Mir ging es darum, dass bei der herkömmlichen und dargestellten Verarbeitung einfach Fehler vorprogrammiert sind, da es keine 100% optimal gescannte Belege bspw. gibt, geschweige denn eine entsprechende OCR-Erkennung – was sich ja auch selbst geschrieben haben.
Wenn jedoch zweifelsfrei hochqualitative (Bank-) Daten vorhanden sind und og. workflow “nachgeschalten” wird, dann sprich gegen automatische Verarbeitung (fast) ** nichts mehr.
Hiermit könnte bspw., ein Ihnen mit Sicherheit bekanntes Projekt, nämlich “Smart Statement” Vorteile erzielen bzw. evtl. haben die Entwickler es dort sogar so umgesetzt.
Mein vorgeschlagener workflow hat also nur Vorteile!
Sollten (Bank) Daten vorhanden sein, ist das Ergebnis fehlerfrei und wenn keine (Bank) Daten vorhanden sind, greift die normale Erkennung.
Ihre Ausführungen über den nächsten Schritt – Weiterverarbeitung/Zahlung – ist individuell zu sehen, denn viele Bekannte/Firmen (in meinem Umkreis) bspw. sprechen sich eindeutig gegen diese Zahlungswege aus.
Gegen Dauerauftrag: unterschiedliche Höhe der Rechnungen (selbst bei Mieten wegen Zusatzl.)
Gegen Lastschrift: Kunde kann nicht selbst Zeitpunkt bestimmen, kein Skonto-Abzug oder einfach das Gefühl “ins Portmonnaie langen” ohne Erlaubnis*
*=auch wenn der Verbraucherschutz (ua. Rücklastschrift) viel besser ist, wie bei fehlerhafter Überweisung
** denkbar wäre auch ein nachträglich Aufbringung von QR-Codes für DMS, SEPA-/girocode, selbst ZUGFeRD-Basis wäre möglich oder ähnl. für digitale Belegzuweisung/-verbuchung wie in DATEV UnternehmenOnline
@Herrn Oesterle
unabhängig von o.g. hab ich mir die Frage gestellt, ob Sie nicht evtl. einen Leitfaden/Tip (neuer Artikel/Blog-Beitrag) geben können, wie die Unternehmen die Belege (Rechnungen/Gutschriften usw.) optimieren können (bspw. Schriftart/-größe/Positionen/optimal Schlagworte), damit diese evtl. einfacher “maschinenlesbar” wären.
Also Ihre Wunschliste im Prinzip 🙂
@Marc
Ich habe inzwischen gerne Ihre Anregung aufgegriffen und einen kleinen Leitfaden auf hybridbanker veröffentlicht: https://www.hybridbanker.de/einfache-digitale-datenextraktion-mit-sechs-standards/
@Herrn Oesterle
vielen Dank 😉 Grüsse nach München
soeben hat organize.me untenstehendes mitgeteilt – was schade, aber meines Erachtens absehbar war – … und selbst wenn man einen Service einstellt, dann sollte dies nicht so kurzfristig erfolgen, denn dies wird bisherige User von Startups abhalten. Eine Mitteilung, dass Entwicklung eingestellt wurde, mit einem freeze des aktuellen Stands für ca. 6-12 Monate, sollten schon umgesetzt werden.
Info von organize.me
… oder wir in den letzten 3 Jahren einfach nicht das umsetzen konnten, was Euch wirklich bei der Bewältigung Eures Papierkrams geholfen hätte. Wir haben es schlicht und einfach nicht geschafft, eine ausreichend große Gruppe von Nutzern für organize.me zu begeistern. Daher mussten wir schweren Herzens eine Entscheidung treffen: Am 29. Februar 2016 wird der organize.me-Dienst eingestellt. Auch die zugehörigen Apps …